type
status
date
slug
summary
tags
category
icon
password
多模态人工智能处于下一波人工智能进步的前沿。事实上,我对2024年生成式人工智能的预测之一是,多模态模型将进入主流,并在年底前成为常态。传统的人工智能系统通常只能处理单一数据类型,如文本,但环顾四周,世界并非单模态的。人类通过多种感官与环境互动,多模态人工智能旨在模仿机器中的这种感知。理想情况下,我们应该能够采用任何组合的数据类型(文本、图像、视频、音频等),并同时将它们呈现给生成式人工智能模型。
大型语言模型(LLMs)当然有其局限性,如有限的上下文窗口和知识截止日期。为克服这些限制,我们可以使用一种称为检索增强生成(RAG)的过程,它包括两个关键步骤:检索和生成。首先,根据用户的查询检索相关数据。然后,这些数据帮助LLM生成特定响应。向量数据库通过存储多样化的数据类型嵌入来支持检索阶段,实现高效的多模态数据检索。这个过程确保LLM能够通过访问最相关的文本、图像、音频和视频数据的组合来生成对用户查询的响应。
在本文中,我们将深入探讨多模态RAG的两个阶段:检索和生成。首先,我们将介绍两种多模态检索方法,这些方法使用向量数据库存储和检索文本和图像数据。其次,对于生成阶段,我们将使用LLMs基于检索到的数据和用户的查询生成响应。
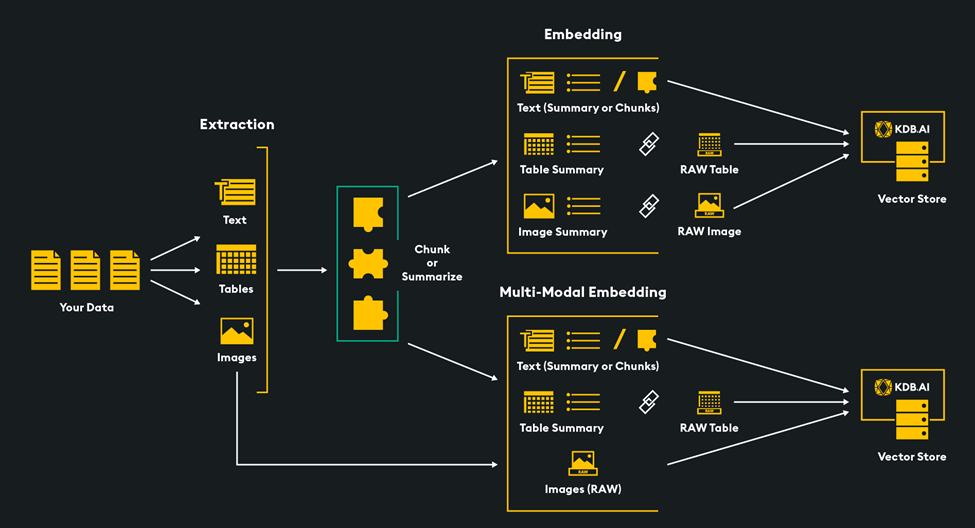
多模态检索用于RAG
检索方法:
我们的目标是将图像和文本嵌入到一个统一的向量空间中,以实现跨两种媒体类型的同时向量搜索。我们通过嵌入数据——将数据转换为数值向量表示——并将它们存储在KDB.AI向量数据库中来实现这一点。有几种方法可以做到这一点,今天我们将探讨两种:
1. 使用多模态 embedding 模型来嵌入文本和图像。
2. 使用多模态LLM来总结图像,将摘要和文本数据传递给文本嵌入模型,如OpenAI的"text-embedding-3-small"。
在本文结束时,我们将介绍如何在理论和代码中实现每种多模态检索方法,使用动物图像和描述的数据集。这个系统将允许查询返回相关的图像和文本,作为多模态检索增强生成(RAG)应用的检索机制。让我们开始吧!
方法1:使用多模态嵌入模型来嵌入文本和图像

文本和图像通过多模态 Embedding 模型进行嵌入的架构
多模态嵌入模型能够将文本、图像和各种数据类型整合到单一向量空间中,从而在KDB.AI向量数据库内实现跨模态向量相似性搜索。然后,多模态LLM可以通过检索到的嵌入进行增强,以生成响应并完成RAG流程。
我们将探索的多模态嵌入模型称为"ImageBind",它是由Meta开发的。ImageBind可以嵌入多种数据模态,包括文本、图像、视频、音频、深度、热成像,以及惯性测量单元(IMU)数据,其中包括陀螺仪和加速度计数据。
ImageBind GitHub仓库:https://github.com/facebookresearch/ImageBind
让我们通过几个代码片段来概述ImageBind的使用。完整的notebook可以在这里查看。
首先,我们克隆ImageBind,导入必要的包,并实例化ImageBind模型,以便稍后在代码中使用:
接下来,我们需要定义函数来帮助我们在数据上使用ImageBind,提取多模态嵌入,并从文本文件中读取文本:
现在让我们设置一个空的数据框来存储文件路径、数据类型和嵌入。我们还将获取一个我们将要存储在向量数据库中的图像和文本的路径列表:
现在是时候遍历我们的图像和文本,并将它们通过我们的辅助函数发送,这些函数将使用ImageBind嵌入数据:
我们现在有了一个包含所有数据的路径、媒体类型和多模态嵌入的数据框!
接下来,我们将设置我们的KDB.AI向量数据库。您可以在KDB.AI免费注册,并获取一个端点和API密钥。
要将我们的数据导入KDB.AI向量数据库,我们需要设置表格架构。在我们的案例中,我们将有一个文件路径列、媒体类型列和嵌入列。嵌入将有1024个维度,因为这是ImageBind输出的维度。相似度搜索方法被定义为'cs'或余弦相似度,索引仅仅是一个平面索引。这些参数中的每一个都可以根据您的用例进行自定义。
确保不存在同名表,然后创建一个名为"multi_modal_demo"的表:
将我们的数据加载到KDB.AI表中!
很好,我们已经将多模态数据加载到我们的向量数据库中。这意味着文本和图像嵌入都存储在同一个向量空间中。现在我们可以执行多模态相似度搜索了。
我们将定义三个辅助函数。一个用于将自然语言查询转换为嵌入的查询向量。另一个用于从文件中读取文本。最后一个用于帮助我们清晰地查看相似度搜索的结果。
让我们进行相似度搜索以检索与查询最相关的数据:
The results!! We retrieved the three most relevant embeddings. Turns out it works pretty well, returning a text description of deer, and two pictures of antlered deer:
结果出来了!我们检索到了三个最相关的嵌入。事实证明它运行得相当不错,返回了一段关于鹿的文字描述,以及两张有角鹿的图片:

方法2:使用多模态LLM总结图像并嵌入文本摘要
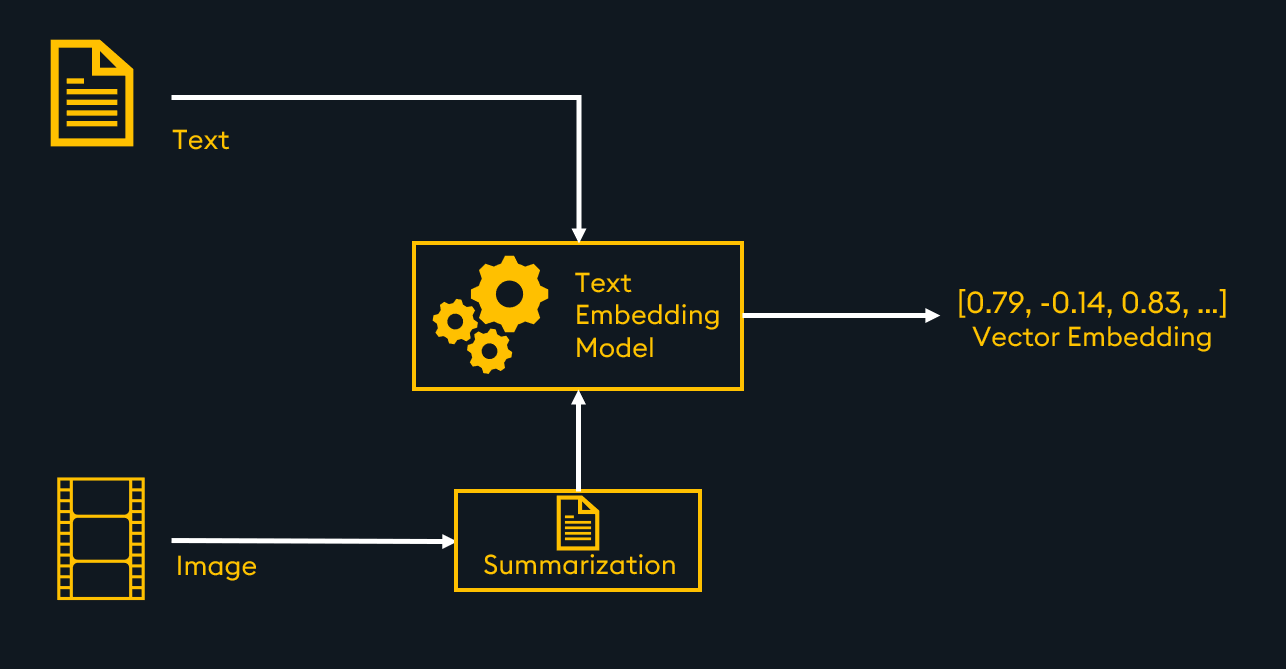
文本和图像摘要通过文本 Embedding 模型进行嵌入的架构
处理多模态检索和RAG的另一种方法是将所有数据转换为单一模态:文本。这意味着你只需使用文本嵌入模型就可以将所有数据存储在同一个向量空间中。这需要额外的成本来初步总结其他类型的数据,如图像、视频或音频,可以手动进行或使用LLM。
将文本和图像摘要都嵌入并存储在向量数据库中后,就可以进行多模态相似度搜索。当检索到最相关的嵌入时,我们可以将它们传递给LLM进行RAG。
现在我们对这种方法有了高层次的理解,是时候深入研究一些代码了!查看完整的notebook以了解详细信息。
首先,我们需要一种方法来总结图像。一种方法是将图像编码为"base64"编码,然后将该编码发送给像"gpt-4-vision-preview"这样的LLM。
要嵌入文本,无论是来自文件还是LLM生成的摘要,都可以使用像"text-embedding-3-small"这样的嵌入模型:
现在让我们设置一个空的数据框来存储文件路径、数据类型、原始文本和嵌入。我们还将获取一个我们将存储在向量数据库中的图像和文本的路径列表:
遍历文本和图像文件,将它们通过我们的辅助函数进行嵌入。为每个文本和图像文件添加一个新行到数据框中,包含相应的路径、媒体类型、文本(或摘要)和嵌入:
我们现在有了一个包含所有数据的路径、媒体类型、文本和嵌入的数据框!接下来我们将设置我们的向量数据库(参见方法1)并创建一个具有以下架构的表:
让我们填充我们的表格:
我们的向量数据库已经加载了所有数据,我们可以尝试相似度搜索:
结果表明这种方法对多模态检索也同样有效!

多模态 RAG
这些方法都可以作为多模态RAG流程中的检索阶段。向量搜索可以返回最相关的数据(包括文本或图像),然后将其注入到提示中发送给您选择的LLM。如果使用多模态LLM,文本和图像都可以用来增强提示。如果使用基于文本的LLM,只需按原样传入文本,并传入图像的文本描述。
下面的架构展示了RAG的高层流程:
- 处理您的数据,进行分块/总结,Embedding
- 将 Embedding 存储在向量数据库中
- 用户查询被 Embedding 并用于对向量数据库进行语义相似度搜索
- 检索到最相关的数据!(在多模态RAG的情况下,包括文本和图像)
- 检索到的数据和用户的查询被发送给 LLM
- LLM生成用户的响应,使用检索到的数据作为上下文来回答用户的查询

原生 RAG 架构
在使用本文描述的检索方法之后,您可以将检索到的数据以文本或图像的形式传递给LLM进行生成,以完成RAG过程。在下面的例子中,我们传入一个检索到的文本数据列表和用户的提示 - 该函数构建一个查询并将其发送给LLM,然后返回生成的响应。
对于接受文本和图像作为输入的多模态LLM的生成,请参见下面使用Google的Gemini Vision Pro模型的代码片段:
对于使用基于文本的LLM进行生成,我们将图像摘要和文本直接传递给LLM,请参见下面使用"OpenAI的gpt-4-turbo-preview"模型的代码片段:
结论
将各种数据类型(如文本和图像)整合到大型语言模型(LLMs)中,增强了它们生成更全面响应用户查询的能力。本文强调了像KDB.AI这样的向量数据库在多模态检索系统核心中的作用,使得相关的多模态数据能够与LLMs耦合,用于RAG应用。今天我们专注于图像和文本,但还有潜力将更多类型的数据整合在一起,为新的AI应用开辟更广阔的前景。多模态RAG的概念是朝着在机器中模仿人类感知迈出的早期但重要的一步。